Realizando backup de servidores Linux no S3 da Amazon
Em resumo nesse tutorial vamos estar Realizando backup de servidores Linux no S3 da Amazon.
Eventualmente esses dias precisei manter uma cópia de arquivos que possuo em meus servidores Linux em um lugar remoto. Obviamente um lugar confiável e seguro, melhor lugar que pensei foi em cloud e escolhi a Amazon para isso.
O serviço S3 deles é impecável e acaba se tornando uma excelente opção inclusive por conta de valores, já cobram apenas upload.
1 – Criar user para fazer a escrita e leitura dos arquivos no S3
Antes de tudo criaremos um usuário no AWS IAM, esse usuário vai ter permissão para escrever nos Buckets do S3. Bucket é o “container” onde irão ficar persistidos os arquivos no S3. Para isso se autentique na console da Amazon e pesquise na busca por: IAM
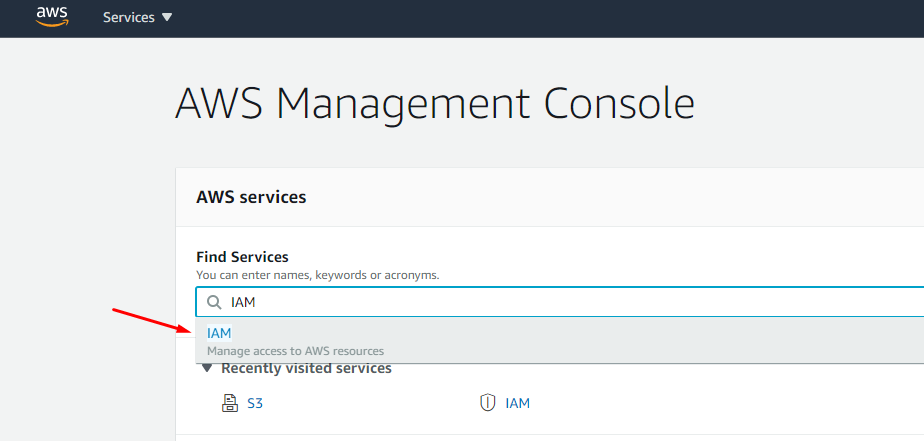
Agora, clique em users -> Add user:
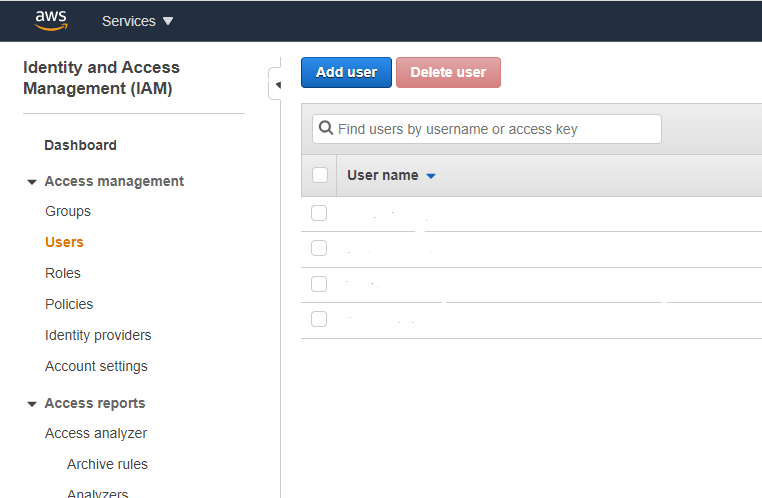
Em seguida digite o nome e marque a opção: programmatic access
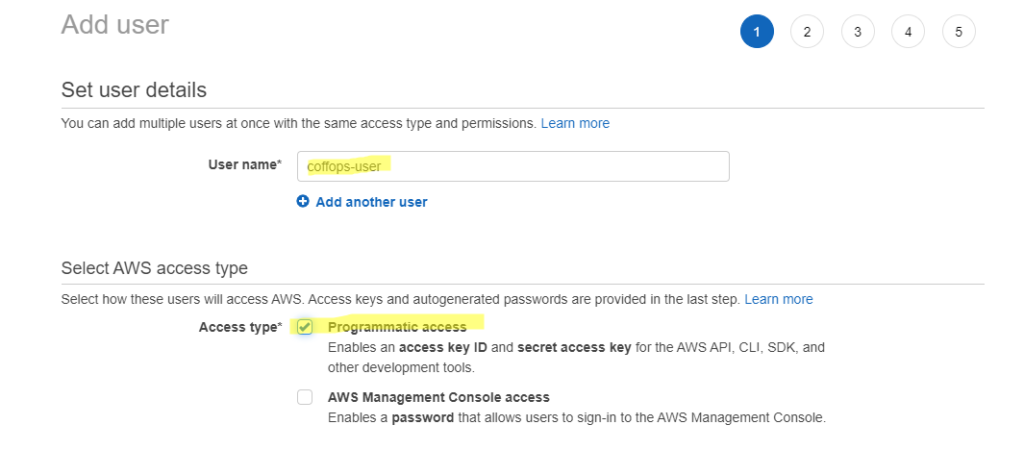
Logo depois defina uma política de acesso para o mesmo:
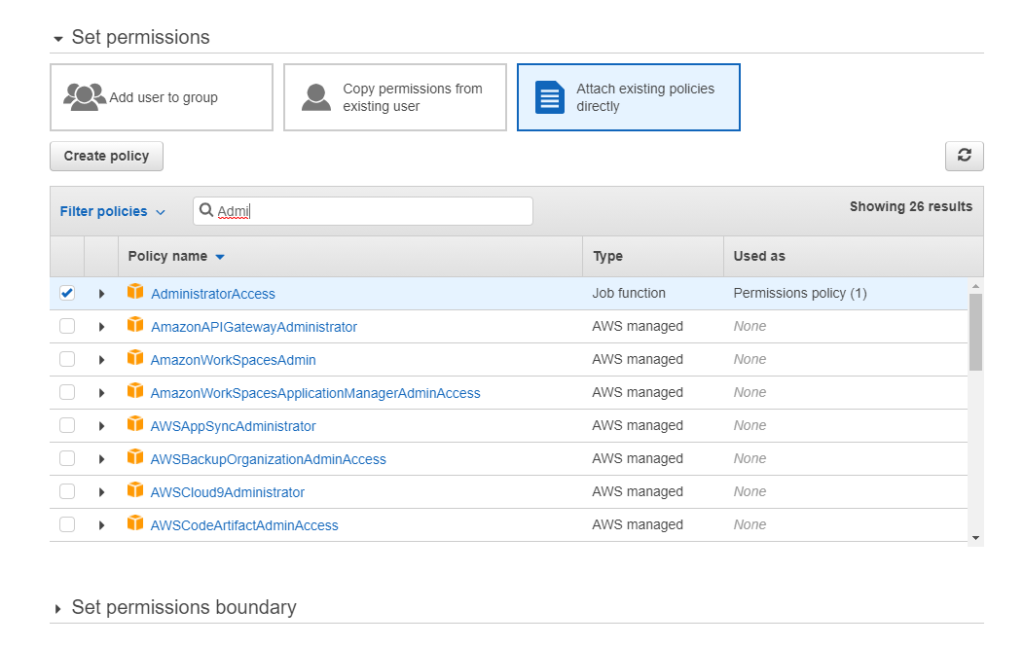
Posteriormente só prossiga com -> Next:Tags -> Next:Review -> Create User, nesse último passo você deve fazer download do .csv que a interface sugere, nesse arquivo estarão o ID e TOKEN que você precisará adiante.
2 – Instalar o command line interface da Aws
Todavia é Facílimo de instalar essa dependência, estou pressupondo que você está em um ambiente linux (no meu caso o CentOS 7) então fará os seguintes passos:
Então entre no diretório /opt e execute os comandos abaixo:
Para baixar o pacote:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
Em seguida temos que extrair o pacote:
unzip awscliv2.zipFinalmente vamos instalar o pacote:
sudo ./aws/installPronto, para testar execute o comando aws –version o retorno será algo assim:
[email protected]# aws --version
aws-cli/2.0.54 Python/3.7.3 Linux/3.10.0-1127.18.2.el7.x86_64 exe/x86_64.centos.7
Caso você precise de mais informações sobre como instalar o aws cli você pode encontrar aqui na documentação da Amazon foi de onde eu extraí esses comandos aí de cima.
3 – Autenticar o aws cli no seu AWS S3
Então, nessa etapa vamos realizar a autenticação do cli no serviço da amazon, é bem simples digite:
aws configureLogo após o passo acima, preencha o formulário com os dados que você baixou no .csv anteriormente, exemplo:
AWS Access Key ID [None]: AQUI_VOCE_COLOCA_O_ID_DO_CSV (ENTER)
AWS Secret Access Key [None]: AQUI_VOCE_COLOCA_O_TOKEN_DO_CSV (ENTER)
Default region name [None]: A_REGIAO_DO_SEU_S3 (meu caso: us-east-1) (ENTER)
Default output format [None]: json (ENTER)Feito, nesse ponto seu cli já está pronto para realizar o upload e enviar seus dados para o S3, vamos agora para parte de como utilizar o CLI:
4 – Comandos para fazer o upload dos arquivos para o S3
Por fim A sintaxe é bem simples, aqui deixarei alguns exemplos de como você pode criar um bucket, fazer upload para e download do mesmo.
Para criar um bucket com o nome de coffops-bucket-1 basta digitar o seguinte comando:
aws s3 mb s3://coffops-bucket-1Feito isso, agora podemos enviar arquivos para esse bucket, logicamente se você já possui um bucket criado não precisa fazer o comando acima.
Vamos supor que queira fazer o upload de um arquivo latinha.mkv que está no diretório /home/coffops para dentro do bucket coffops-bucket-1 basta executar o seguinte:
aws s3 cp /home/coffops/latinha.mkv s3://coffops-bucket-1/O comando acima irá enviar o arquivo para a raiz do bucket, caso você queira fazer o download desse arquivo é só inverter a origem e o destino:
aws s3 cp s3://coffops-bucket-1/ /home/coffops/latinha.mkvEasy!
Por último quero deixar um cenário aqui que provavelmente é o que eu mais utilizo é o famoso Sync. Vamos supor que eu queira enviar para o S3 sempre os arquivos que forem criados, e não enviar todos os arquivos toda vez que eu fizer o upload, clássico cenário para backup, você pode utilizar o argumento sync, veja o exemplo:
Em suma você tem uma pasta chamada /home/coffops e quer fazer uma cópia diária do que tem nesse diretório e enviar só os arquivos novos para o S3 sem sobrescrever os que já existem, nesse caso faça:
aws s3 sync /home/coffops s3://coffops-bucket-1/coffops-homeCom o comando acima será copiado todo o diretório /home/coffops para dentro de uma pasta desse bucket chamada coffops-home, se você rodar novamente esse comando ele irá só enviar os arquivos novos ou alterados.
Acima de tudo caso esse post tenha lhe ajudado em algo deixe-nos saber comentando aqui embaixo. Esperamos que você já esteja Realizando backup de servidores Linux no S3 da Amazon
Minha referência foi essa aqui.
Nesse meio tempo você pode gostar também: Falha na Atualização do Firmware PERC 6/I Dell R610